En el post anterior, hablamos a nivel general sobre crear e implementar soluciones de IA generativa, poniendo el foco en los chatbots. En este artículo, queremos bajar más a tierra y mostrar los componentes tecnológicos que se necesitan para armar este tipo de soluciones, explicando cómo funcionan en conjunto y qué papel cumple cada uno. También vamos a contarles qué ventajas hemos visto en ixpantia al usar estas tecnologías. Espero que esta información te sirva. Y recuerda, cualquier duda que tengas, pregunta que estamos para ayudarte.
Nuestro caso de Estudio
Data Latam es una comunidad auspiciada por ixpantia, de personas entusiasmadas con la Ciencia de Datos. Una de las cosas que se hacen en Data Latam es un podcast donde realizamos entrevistas sobre temas de actualidad y experiencias en el mundo de los datos. Con tantos episodios acumulados, nos dimos cuenta de que empezaba a ponerse difícil encontrar citas o referencias puntuales de algún tema. Por eso se nos ocurrió crear un chatbot que pueda responder preguntas basadas en el contenido de los podcasts.
Diseño de la solución
La idea es hacer un proceso que consuma los podcasts, los transcribe a texto usando un modelo de transcripción automática, y con ese texto entrene a un modelo de lenguaje natural. Después, crear una interfaz de chatbot para hacerle consultas y que responda con base en lo que aprendió.
Como se suman nuevos episodios cada 2-3 semanas, sería conveniente automatizar la transcripción, el entrenamiento y la actualización del modelo, así no hace falta que nadie tenga que hacer esta tarea tediosa cada vez. En la transcripción y el entrenamiento se necesitan recursos costosos, que deberían estar disponibles solo el tiempo necesario. Y el chatbot en sí tiene que ser un servicio eficiente, escalable y de alta disponibilidad.
Componentes de tecnología
Para hacer esto, haría falta:
- Una herramienta que maneje el flujo de trabajo, conectando todos los componentes, haga seguimiento y responda cuando pregunten en qué estado están las cosas.
- Un modelo pre-entrenado para transcribir automáticamente.
- Una máquina virtual donde corra el modelo de transcripción.
- Un lugar para guardar los textos transcritos.
- Un modelo de lenguaje natural que se ajuste a base de las interacciones esperadas y los textos.
- Un modelo de embeddings que transforme el texto en vectores.
- Una máquina virtual para volver a entrenar el modelo.
- Un servicio para publicar el chatbot, con el modelo para responder consultas, una API y una interfaz copada.
- Un mecanismo que “levante” y “baje” infraestructura cuando haga falta.
- Un componente que facilite instalar el software siguiendo los requerimientos.
- Herramientas y servicios para coordinar la instalación del software.
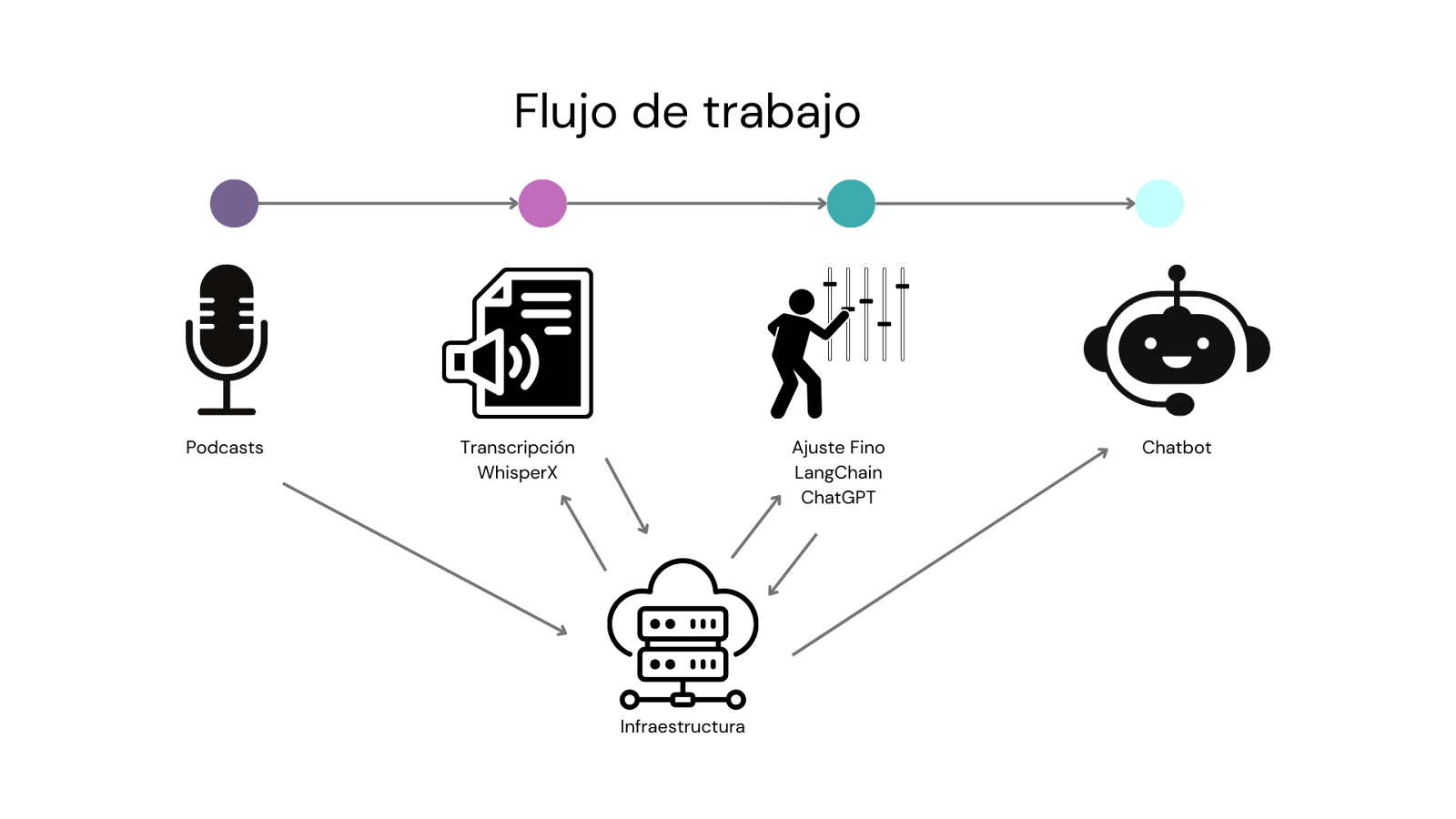
Fig. 1: Componentes de tecnología
Flujo de trabajo
Las herramientas de flujo de trabajo ayudan a automatizar y administrar todo el proceso de poner modelos de IA en producción.
Básicamente lo que hacen estas herramientas es interconectar y seguir de cerca los procesos de:
- Conseguir y pre procesar datos.
- Entrenar, evaluar, implementar y monitorear los modelos ya en producción.
Usar una herramienta de este tipo te da una plataforma centralizada para integrar todas las piezas, en lugar de tener scripts separados, lo que es muy ventajoso a la hora de gestionar un proyecto de IA.
En nuestro caso usamos Python para implementar el flujo, que suele ser la primera opción como lenguaje dinámico. R o Julia también son opciones muy apropiadas. La idea es encadenar componentes de software que van haciendo los diferentes pasos para transformar los datos en soluciones ágiles.
Transcribiendo los podcasts
El término genérico para los modelos de transcripción es “Reconocimiento Automático del Habla” (Automatic Speech Recognition o ASR en inglés). Son herramientas que transcriben audio, como reuniones, entrevistas o podcasts, para después analizarlo. Algunos usos son mejorar la accesibilidad de contenidos de audio/video agregando subtítulos, permitir comandos de voz y asistentes virtuales, o transcribir llamadas telefónicas.
Al igual que en otras áreas de la IA, hay distintos modelos de ASR disponibles como servicios o modelos pre-entrenados. O sea, componentes de software que ya saben recibir archivos de audio como entrada y devolver el texto correspondiente a ese audio, sin necesidad de complicarse demasiado. Uno de los modelos más conocidos es Whisper de OpenAI.
Nosotros usamos WhisperX porque es igual de fácil que Whisper pero más rápido para procesar. Se puede usar desde la línea de comandos o con Python.
Para ver un ejemplo, puedes probar con el famoso archivo de audio del “Houston, tenemos un problema” de la misión Apollo 13. Lo divertido es que lo puedes instalar en tu propia computadora siguiendo el README del repositorio.
Si descargamos el archivo en nuestro sistema de archivos y ejecutamos WhisperX en nuestra línea de comandos, obtenemos lo siguiente:
$whisperx Apollo13-wehaveaproblem_edit_1.ogg --compute_type int8
Generando el siguiente archivo:
1
00:00:00,302 --> 00:00:01,944
Okay, we've had a problem here.
2
00:00:03,066 --> 00:00:04,328
This is Houston, say again, please.
3
00:00:05,409 --> 00:00:06,410
Oh, Houston, we've had a problem.
4
00:00:08,033 --> 00:00:09,475
We've had a main beam, plus undervolt.
5
00:00:11,037 --> 00:00:13,179
Roger, main beam, undervolt.
6
00:00:14,341 --> 00:00:16,103
Okay, stand by at 13, we're looking at it.
Es la parte de la conversación entre Lovell y Lousma que pueden encontrar en: https://history.nasa.gov/afj/ap13fj/08day3-problem.html
No solamente nos indica el texto contenido en el audio, sino además nos indica con gran precisión en qué punto del audio se menciona, lo que es muy útil para subtitular cualquier contenido.
Ejecutando los modelos
En lugar de utilizar las capacidades de la computadora que tienes en el escritorio, puedes alquilar una parte de una computadora poderosa que está en algún lugar lejano, en un centro de datos. Accedes a esta computadora, la configuras y la usas a través de Internet.
Esta computadora de alquiler o “máquina virtual” actúa como tu propia computadora personalizada, donde puedes instalar software, almacenar datos y realizar tareas como si estuvieras frente a una computadora física.
La utilidad principal de esto es que no necesitas preocuparte por mantener la infraestructura física; simplemente pagas por el tiempo que usas estas máquinas virtuales, lo que puede ser muy conveniente y rentable, especialmente para empresas que necesitan flexibilidad y no quieren lidiar con la gestión de hardware.
En nuestro caso, queríamos la computadora para poder ejecutar whisperX sobre nuestros archivos de audio del post. Ya que este proceso requiere gran poder de cómputo, su uso es costoso. Por esta razón necesitábamos también una herramienta que creara la máquina virtual de forma automática, es decir, sin necesidad de que una persona esté haciendo clics en una interfaz cada semana, solamente durante el tiempo necesario, y una vez finalizado el procesamiento la diera de baja.
Para lograr este objetivo de levantar y dar de baja la infraestructura automáticamente utilizamos Terraform. Esta es una herramienta de “infraestructura como código” porque pone a nuestra disposición servicios computacionales de acuerdo a instrucciones de código.
Almacenamiento de información
De la misma forma que requerimos un servicio de cómputo “virtual”, también era necesario contar con espacios de disco “virtuales”, es decir alquilar una parte de la capacidad de almacenamiento del proveedor del servicio, para almacenar los archivos de audio de los podcast, las transcripciones, y cualquier otro archivo adicional que necesitemos.
En general, es conveniente que todos los servicios sean del mismo proveedor para maximizar la velocidad de transferencia de la información, y en consecuencia reducir los costos operativos de la solución.
De nuevo Terraform acudió en nuestra ayuda para configurar, si era necesario, cualquier espacio de almacenamiento temporal que fuese necesario.
Respondiendo a las preguntas sobre los podcasts
Ya tenemos los podcast en archivos de texto, que es la forma más conveniente de introducir esta información a un componente de software “que hable”. Este componente que habla no es más ni menos ChatGPT, el producto más famoso de OpenAI, la start-up más famosa y mediática (si has estado pendiente de los últimos chismes en tecnología) de soluciones de IA.
ChatGPT es, al igual que whisperX, un modelo pre-entrenado. Este tipo de modelos que hacen que el software “hable” se conocen como modelos de lenguaje de gran tamaño (o, del inglés LLM o Large Language model) es un sistema de IA entrenado con una enorme cantidad de texto que le permite al modelo, básicamente, predecir qué es lo más conveniente que debe decir a partir de un contexto.
Este contexto, es, de forma muy simplificada, es a lo que se refieren cuando hablan de los “parámetros” del modelo.
Al igual que con Whisper, ChatGPT no es la única alternativa, hay una gran variedad de modelos con capacidades técnicas similares que son viables dentro del alcance de nuestro proyecto, opciones como el modelo Open Source Llama, o la competencia directa de Google Bard. Sin embargo, seleccionamos ChatGPT porque en el momento actual es la mejor opción -como producto-.
Ya tenemos nuestra máquina hablante, pero necesitamos que hable de lo que nos interesa a nosotros. ChatGPT no sabe del contenido de los podcast de DataLatam, así que hay que enseñarle.
Para que ChatGPT pueda entender y procesar textos, como por ejemplo los del podcast de DataLatam, es necesario convertir estos textos en un formato que el modelo pueda interpretar. Este proceso se llama ‘creación de embeddings’. Los modelos de embeddings son una forma de convertir texto en números que reflejan el significado y el contexto de las palabras. En este caso utilizamos el modelo text-embedding-ada-002 que ofrece OpenAI, para tal propósito.
Ahora que tenemos todas las partes, necesitamos integrarlas y para lograrlo, utilizamos un par de herramientas novedosas que han surgido del auge reciente de la IA: langchain, una biblioteca que nos ofrece una interfaz común para comunicarnos con los modelos, así si queremos en el futuro utilizar otro modelo en lugar de ChatGPT será mucho más fácil; y chromaDB un motor de bases de datos vectorial donde se almacenan los vectores que representan el texto. ChromaDB ayuda al chatbot a entender cómo están relacionados los documentos y las palabras que contienen. De esta manera, cuando alguien pregunta algo, el chatbot puede usar ChromaDB para encontrar la respuesta correcta en los documentos de forma rápida y precisa. Piensa en ChromaDB como un índice muy avanzado que ayuda al chatbot a navegar y entender una gran biblioteca de información.
Esquema del proceso de ChatDL
El esquema describe el proceso de ChatDL, que responde preguntas sobre documentos, específicamente transcripciones de podcasts de DataLatam.
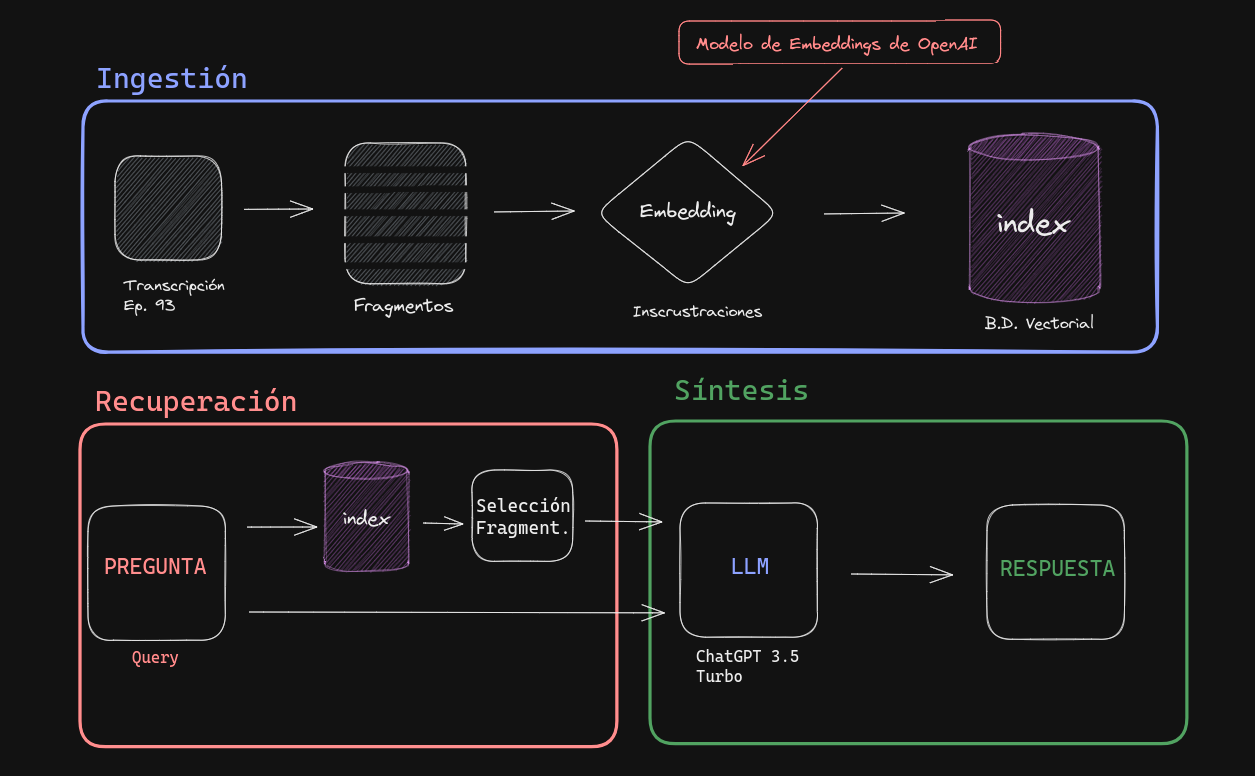
Fig. 2: Esquema de ChatDL
Ingestión
- Transcripción: El proceso comienza con la transcripción del episodio número 93 del podcast de DataLatam.
- Fragmentos: La transcripción se divide en fragmentos más pequeños para su procesamiento.
- Embedding: Cada fragmento se procesa mediante un modelo de embeddings de OpenAI (text-embedding-ada-002) para convertir el texto en una representación vectorial que puede ser entendida por máquinas.
- Indexación: Los embeddings se almacenan en una base de datos vectorial (ChormaDB) que permite su recuperación eficiente.
Recuperación
- Pregunta (Query): Cuando se hace una pregunta a ChatDL, esta se convierte en una consulta (query).
- Index: La consulta se usa para buscar en el índice de la base de datos los fragmentos más relevantes.
- Selección de Fragmentos: Se seleccionan los fragmentos que mejor coinciden con la consulta.
Síntesis
- LLM (ChatGPT 3.5 Turbo): Los fragmentos seleccionados se pasan al modelo de lenguaje (Large Language Model), en este caso ChatGPT 3.5 Turbo. Y también la “pregunta” que se quiere contestar.
- Respuesta: Finalmente, el modelo de lenguaje genera una respuesta basada en la información recuperada de la base de datos y la pregunta que se quiere responder.
En resumen el esquema ilustra cómo ChatDL utiliza técnicas avanzadas de procesamiento de lenguaje natural y búsqueda de información para responder preguntas específicas basadas en el contenido del podcast.
Ahora un poco de Código
Una función Python como la siguiente resume el proceso básico:
llm = ChatOpenAI(temperature=0, openai_api_key=openai_api_key, model=model_name)
def procesar_documento(nombre_archivo, directorio, openai_api_key):
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
loader = TextLoader(nombre_archivo, encoding="utf-8")
doc = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=400)
docs = text_splitter.split_documents(doc)
chroma = Chroma.from_documents(docs, embeddings, persist_directory=directorio)
return chroma
A continuación, procesamos el texto del podcast de la siguiente manera:
chroma_podcast_10 = procesar_documento(
"./transcripciones/datalatam-podcast-episodio-10.txt", "./chroma_dbs/chroma_db_podcast_10"
)
Y lo consultamos como sigue:
qa_podcast_10 = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=chroma_podcast_10.as_retriever()
)
query = "Dame un resumen"
respuesta_podcast_10 = qa_podcast_10.run(query)
print(respuesta_podcast_10)
Obteniendo:
En este fragmento de una entrevista, Diego y Franz hablan con Vanessa Delacqua, una experta en Big Data y ciencia de datos. Vanessa cuenta que es ingeniera de software y tiene más de 20 años de experiencia en el campo de la computación y desarrollo de software. Comenta que fundó su propia empresa y ha trabajado en proyectos de datos desde el año 2013. Vanessa destaca la importancia de utilizar técnicas y tecnologías de ciencia de datos para obtener respuestas correctas a partir de la información disponible. Franz también menciona la diferencia entre Big Data, que se enfoca en la infraestructura, y la ciencia de datos, que se centra en la metodología y la resolución de preguntas de manera innovadora. Vanessa menciona que el cambio de enfoque hacia soluciones más tradicionales puede ser un desafío, pero es necesario encontrar un equipo que comprenda el proceso
Así, el modelo construye una respuesta a partir de la información de la transcripción. Hay un componente aleatorio en la generación de la pregunta de manera tal que aunque realices la misma pregunta varias veces, vas a recibir respuestas con algunas variaciones.
Respondiendo desde la web
Finalmente, contamos con una función que me da respuestas sobre los distintos podcasts de DataLatam. Ahora, ¿cómo hacemos para que esté disponible para cualquier usuario del sitio web?. Pues la respuesta es: convertirlo en un servicio, lo que en términos técnicos se traduce en: proveer a esa función de una máquina donde correr, un entorno de software con todo lo necesario, y una forma de comunicarse con una interfaz donde el usuario pueda introducir sus preguntas.
La máquina donde correr, y el entorno de software que necesita la función para ejecutarse se resuelve con con contenedor, esto es, siguiendo la analogía del transporte marítimo, una caja simbólica que permite trasladar nuestros programas de una lugar a otro garantizando que cuente con todo lo necesario para garantizar su operación.
La forma de comunicarse de este programa con el exterior requiere de un punto de conexión y un protocolo de comunicación, esto se resuelve con una API (esto es, del inglés Application Programming Interface, una Interfaz de programación de aplicaciones). Un mecanismo ampliamente utilizado que permite una forma estándar en que los programas se comunican entre sí. El programa corriendo en un contenedor, que ofrece comunicación mediante un API, en especial cuando realiza una única tarea bien definida, como atender preguntas sobre el contenido de los podcast, es lo que se conoce como un ejemplo de microservicio.
Este API ofrece un punto de conexión al que, en primera instancia un formulario web en la página web de DataLatam, y eventualmente, cualquier aplicación en Internet que cuente con el acceso y los permisos adecuados, pueda hacer consultas sobre el contenido de los podcasts mediante el habla natural.
Si le hacemos preguntas sobre el Podcast 20:

Fig. 3: Podcast 20 de DataLatam
Podemos obtener una respuesta como la siguiente:
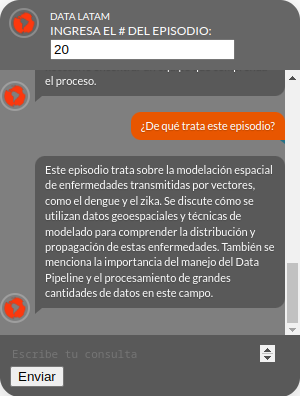
Fig. 4: Interfaz de ChatDL
Como ganancia adicional, el modelo de ChatGPT fue entrenado y “sabe” hablar en una gran cantidad de idiomas, e intentará expresar de la mejor manera que pueda la información recién adquirida. Así que nuestra solución de consulta es capaz de detectar el idioma de la pregunta y responder en consecuencia.
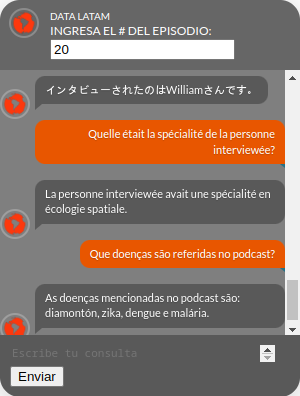
Fig. 5: ChatDL respondiendo a distintos idiomas
¿Qué te ha parecido?, en ixpantia estaremos encantados de desarrollar una herramienta de este tipo para tu organización, buscando siempre el mejor equilibrio entre innovación, los objetivos estratégicos del negocio, y el presupuesto. Te agradecemos cualquier comentario sobre el uso de estas herramientas en las organizaciones, el cambio organizacional que estas demandas y los desafíos técnicos que plantean.
Puedes interactuar con nuestro chatbot con el siguiente botón:
Este blog lo mantiene el equipo de ixpantia y la comunidad de gente interesada en datos de la cual estamos contentos de formar parte ¿Tienes una idea para publicar algo aquí? ¡Escríbenos! Estamos siempre interesados en material e ideas nuevas.




